
This blog post is the second in a series about AI data delivery.
As AI usage accelerates, data pipelines must scale even faster to prevent bottlenecks and maintain performance. Recent research from firms such as McKinsey & Company shows that the appetite for AI-ready data center capacity is expected to grow by approximately 33% per year through 2030. This means that even the best model architectures will be starved of data unless the delivery pipeline scales accordingly.
But as AI workloads scale, organizations are quickly discovering a surprising truth: the slowdowns rarely come from the model training or fine-tuning process itself; they come from the upstream data pipeline that must continuously supply the model foundry with high-volume, high-quality data.
“New innovations enable F5 BIG-IP to deliver the intelligent traffic management, data path optimization, and security controls needed to keep AI data moving at high volume and high velocity across training, embedding-generation, and fine-tuning workflows.”
Modern AI systems depend on fast, predictable movement of data between object stores, retrieval layers, feature pipelines, and embedding-generation workflows—as well as inference endpoints where applicable. When this “flow” slows down, performance collapses, GPUs sit idle, and the time to value for the enterprise to begin realizing value takes longer than expected.
A useful analogy is the oil pipeline, which we referenced in the first blog post in this series. You may have the most advanced refinery in the world—meaning, the large language model (LLM), the vector search engine, or the multi-modal model-foundry cluster used for training, fine-tuning, or producing embeddings. But if the pipelines feeding that refinery are narrow, leaky, or congested, production grinds to a halt. The refining process isn’t the problem; the transportation system is. Today’s AI pipelines operate under the same principle: the flow of data determines the performance of the system.
Where AI bottlenecks truly form
AI pipelines rarely burst at a single point; they slow down across a chain of micro-interactions. A single workflow might involve pulling training datasets, enterprise knowledge repositories, or embeddings from object storage, transforming that data for ingestion, querying a vector store, hitting multiple microservices, and only then moving into fine-tuning or model-build steps.
Each step introduces potential friction. Individually the delays look negligible, but when combined, they inflate end-to-end processing times and starve GPUs of the data they need, especially in high-volume training or augmentation jobs.
It’s the equivalent of an oil pipeline suffering from reduced pressure, valve misalignment, and unexpected surges. The flow becomes inconsistent, and downstream facilities never receive a steady, predictable supply. AI model foundry systems experience the same phenomenon when storage nodes slow down, network paths degrade, or workloads spike unpredictably.
Available research makes it extremely clear: AI performance problems usually stem from the data pipeline, not the model. In a Fivetran survey, 42% of enterprises reported that more than half of their AI projects were delayed or that they under-performed or failed because their data wasn’t ready or accessible in time.
Another study from Broadcom found that 96% of organizations say data pipeline performance issues directly impaired their AI objectives, leading to delays in training and preparation workflows, reduced automation, and costly rework.
These numbers reveal a critical truth: when data can’t move quickly or reliably through the pipeline, even the the most sophisticated model foundry operations can’t deliver consistent results.
How F5 BIG-IP modernizes AI data delivery
With the release of F5 BIG-IP version 21, BIG-IP has evolved well beyond its role as a traditional application delivery controller (ADC). It now serves as a fully modernized ADC designed for AI-driven data pipelines, particularly those built around S3-compatible object storage.
New innovations enable F5 BIG-IP to deliver the intelligent traffic management, data path optimization, and security controls needed to keep AI data moving at high volume and high velocity across training, embedding-generation, and fine-tuning workflows, not just inference.
It is designed to stabilize and accelerate the entire flow. Sitting as a delivery tier between the object store and the AI application stack, it ensures that data ingress, retrieval, and routing remain smooth, secure, and resilient, even under intensive load.
BIG-IP continually monitors the health of storage nodes and automatically reroutes traffic away from slow or failing endpoints. Its S3-specific optimizations, such as enhanced TCP/TLS profiles for large multipart uploads, help reduce request overhead and accelerate high-volume reads. Traffic can also be directed based on metadata, such as object size, prefix, or bucket, enabling organizations to prioritize fine-tuning datasets, training artifacts, or RAG embedding data differently based on operational needs.
Key pillars: location-aware routing, caching, and security
Another significant factor in the effectiveness of BIG-IP is how it handles location-aware routing. When a storage region experiences latency or a cluster undergoes maintenance, flows are seamlessly redirected to a healthy site without requiring changes to the applications themselves. This keeps the AI pipeline continuously supplied with data, regardless of what’s happening in the storage layer behind it.
Traffic management and security must be firmly integrated into the data transport ecosystem. AI data endpoints are expensive to run and valuable to attackers. As is shown in the diagram below, BIG-IP provides key delivery and security capabilities to AI data pipelines. Advanced DDoS protection, WAF capabilities, and fine-grained API governance, make security part of the data pipeline rather than a choke point in it.
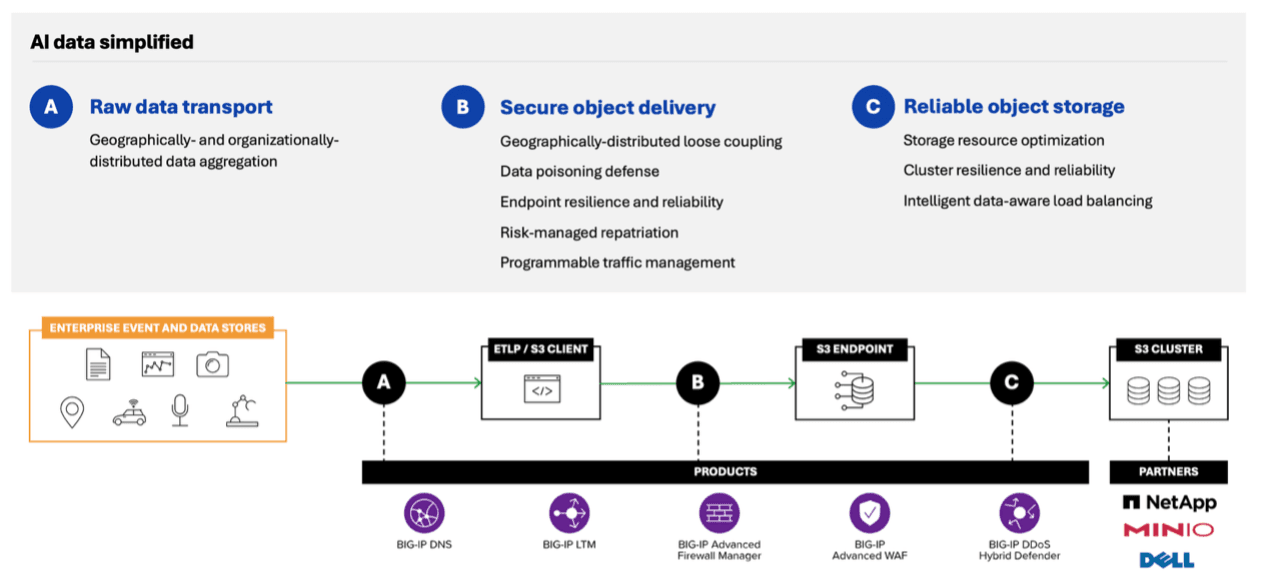
The importance of resiliency and reliability
Even optimized pipelines face disruptions. Traffic surges, node failures, replication bursts, and network changes can all degrade AI performance. Resilience is the ability to keep the data flowing despite these conditions. BIG-IP thrives at this by offering active failover, traffic draining during maintenance events, and programmable routing policies that keep the pipeline stable.
In practical terms, this means data stores stay available and accessible. Training cycles maintain momentum. RAG embedding and data-augmentation processes complete on schedule. And the business avoids the cascading failures that occur when one layer of the AI stack becomes overloaded or unavailable.
BIG-IP acts like the pressure-control, flow-balancing, and safety-valve system for the entire AI data pipeline. It ensures that the refinery, a.k.a. the AI model foundry, always has the steady stream of high-quality “oil” it needs.
F5 delivers and secures AI applications anywhere
AI performance optimization isn’t just about model inferencing. It’s about ensuring that the massive volumes of data required for training, fine-tuning, and embedding workflows move quickly, predictably, and securely.
For more information about our AI data delivery solutions, visit our AI Data Delivery and Infrastructure Solutions webpage. Also, stay tuned for the next blog post in our AI data delivery series focusing on building the generative AI data pipeline.
F5’s focus on AI doesn’t stop with data delivery. Explore how F5 secures and delivers AI apps everywhere.
________________________________________________________________
Be sure to check out our previous blog post in the series:
Fueling the AI data pipeline with F5 and S3-compatible storage
About the Author

Related Blog Posts
Secrets to scaling AI-ready, secure SaaS
Learn how secure SaaS scales with application delivery, security, observability, and XOps.

Optimizing AI pipelines by removing bottlenecks in modern workloads
As AI workloads scale, organizations are discovering slowdowns that come from the upstream data pipeline that feeds the AI model. Here's how F5 BIG-IP can help.
Why SASE and ADSP are complementary platforms
SASE secures the hybrid workforce and ADSP secures the hybrid application estate. Learn how these converged platforms differ and why they complement each other.

Fueling the AI data pipeline with F5 and S3-compatible storage
When S3-compatible storage is paired with F5 BIG-IP, organizations can ensure their AI data pipelines stay resilient, secure, and always flowing at peak performance.

How AI inference changes application delivery
Learn how AI inference reshapes application delivery by redefining performance, availability, and reliability, and why traditional approaches no longer suffice.
Why XOps is critical for the technology sector
XOps treats AI as a platform capability, integrating AI into infrastructure, security, and operational strategies to better support a company’s applications.